Daily Trend [11-02]
【1】Frozen Transformers in Language Models Are Effective Visual Encoder Layers
【URL】http://arxiv.org/abs/2310.12973
【Time】2023-10-19
一、研究领域
LLM for Visual Tasks
二、研究动机
“As we explore the limits of utilizing LLMs for computer vision tasks, an interesting question arises: can LLMs effectively handle tasks that are exclusively visual, without any reliance on language?” (感觉这里翻成中文就莫得灵魂了,所以直接引原文的话)
三、方法与技术
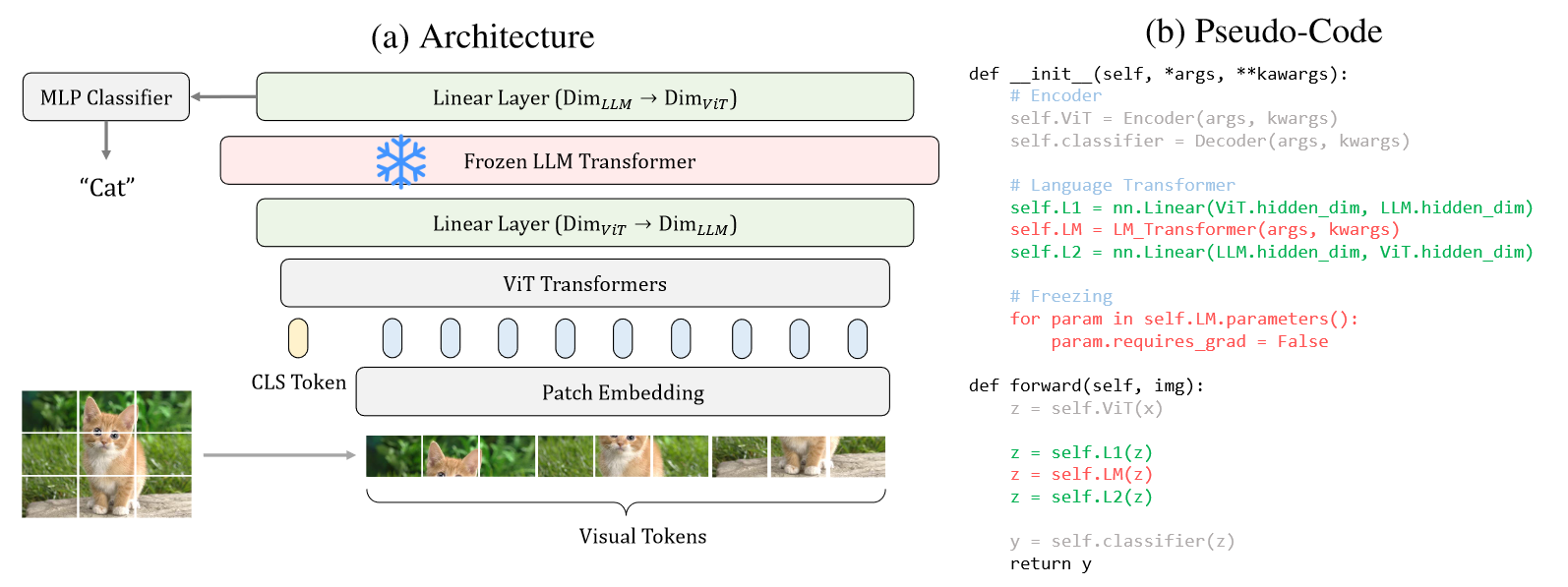
(1)从 LLaMA 里取一个预训练的 transformer block ,夹在两个 linear 层中间
(2)把它们夹到一个预训练的 visual Encoder & Decdoer 中间
(3)使用上述结构,更换不同的 visual framework 和 task 进行不同的微调测试,仅 linear 层可训练
*注意,为了让 LLM block 适应视觉任务,去除了auto-regressive mask 和 positional embedding。
四、总结
大概意思就是发现加了frozen llm block以后,视觉编解码器的注意力变得更干净准确了,实验挺有趣全面的,可以去文章里看看。
【2】LanguageBind: Extending Video-Language Pretraining to N-modality by Language-based Semantic Alignment
【URL】http://arxiv.org/abs/2310.01852
【Time】2023-10-23
一、研究领域
多模态对齐
二、研究动机
提出一种基于language的多模态预训练框架,可以将video-language预训练扩展到多种 (N) 模态(由于语言模态包含丰富的语义信息并且已被充分探索,所以将其视为不同模态之间的binder)。
三、方法与技术
包含三部分:
(1)multi-modal encoders:除了language之外的其它模态的编码器都用24-layer,1024-dim的vision transformer实现,初始化权重用OpenCLIP-large,然后通过token masking和LoRA来训练不同模态的编码器。
(2)language encoder:用12-layer,768-dim的transformer实现,初始化权重用OpenCLIP,tokenizer用BPE实现。
(3)multi-modal joint learning:每个模态都通过对比学习和language对齐。
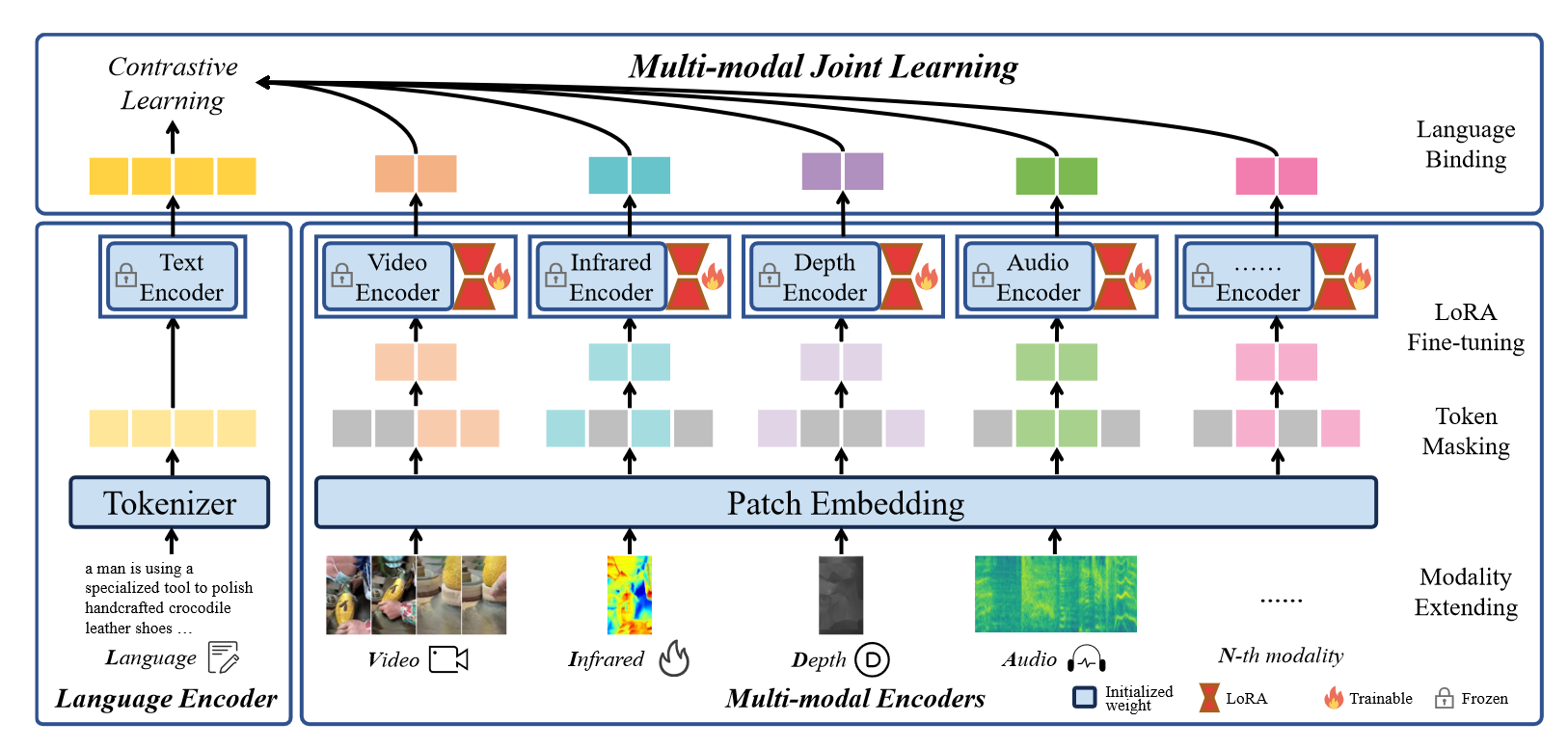
语言编码器参数被冻结,而多模态编码器参数可以使用 LoRA 技术进行调整。通过采用语言和其他模态之间的对比学习,LanguageBind 成功实现了多模态联合学习,从而促进了不同模态之间的语义对齐。
为了实现训练,构造了一个多模态大数据集:
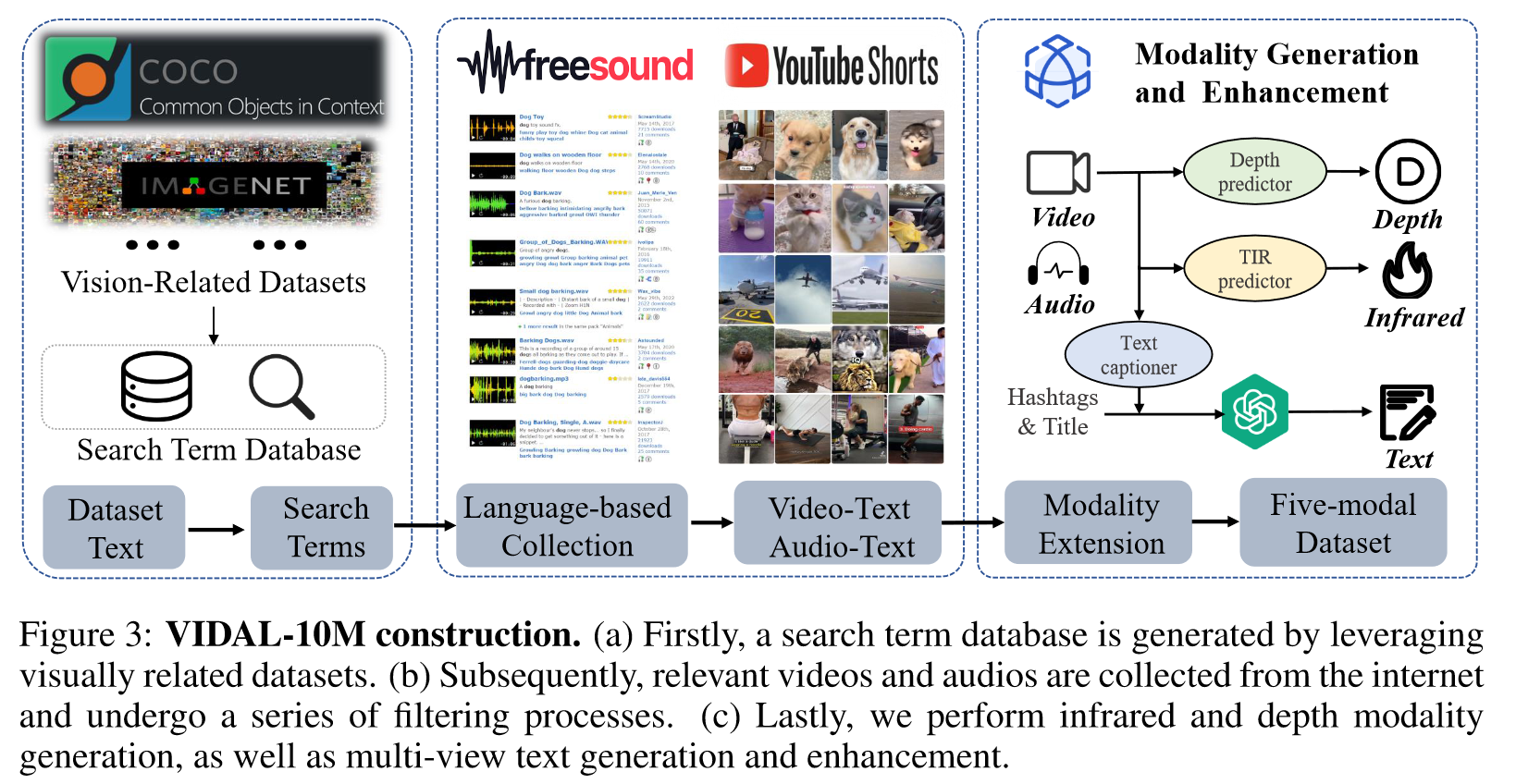
四、总结
方法上比较直接,核心贡献是构建了第一个直接与语言模态对齐的大规模多模态数据集 VIDAL-10M
五、推荐相关阅读
ImageBind: One Embedding Space To Bind Them All